Video Search Engine
Team: JAX(One Champion in League of Legends, also the combination of our first names initials)
Members:
Xingwen Zhang xingwenz@usc.edu
Alexander Grieco griecoa@usc.edu
Jiahui Yang jiahuiya@usc.edu
Motivation
Now the video search engine is usually text-based. The search engine collects the videos’ features as text content, then organize them with some rules. However, sometimes the text feature is hard to descript, therefore, users sometimes need to search the video by some video clips or by the audio part.
Our video search engine works in such case. It fetches the video feature directly rather than by the text elements like the video title, video description etc.
Method
For the trade off between the accuracy and searching speed. Our group takes use of three methods to rank all the candidates videos by descending order.
Motion
Inspired by the video compression algorithm, we know that there is some relation between the nearby video frames. For example, one cat is walking, then the two nearby frames are similar but with little difference. We could detect the little difference using vector.
By using this method, the video could be transferred to a series of motion vector. When needed, the engine could compare the candidates’ motion vectors with video clips’.
Color
It is intuitive, for each frame, it might contain top 5 dominated colors. And then we could use the top colors as the elements that could be compared.
The key point is how to find the top 5 colors efficiently. We tried the K-means, count, range count methods. K-means is a typical machine learning clustering method. It return the top N cluters. It has great accuracy, however, it runs too slow. Count is simple, but still a little slow. The range count is a tradeoff. It doesn’t count the accurate color appearence time, however, similar color counted as one group. It works well in our group.
Audio
The key for audio is to find the key feature of audio files. It uses the Fourier Transform to transfer the time-domain data to frequency-domain. After that, pick the specific frequency range’s peak value as their feature.
By using the FFT and select the reasonable frequency range(e.g. 200HZ to 2000HZ which cover the most common voice, like human voice or some instrument), it runs very fast with rather high accuracy.
However, the disadvantage is sometimes, the videos have similar content but with quite different background music. At this time, this method doesn’t work well.
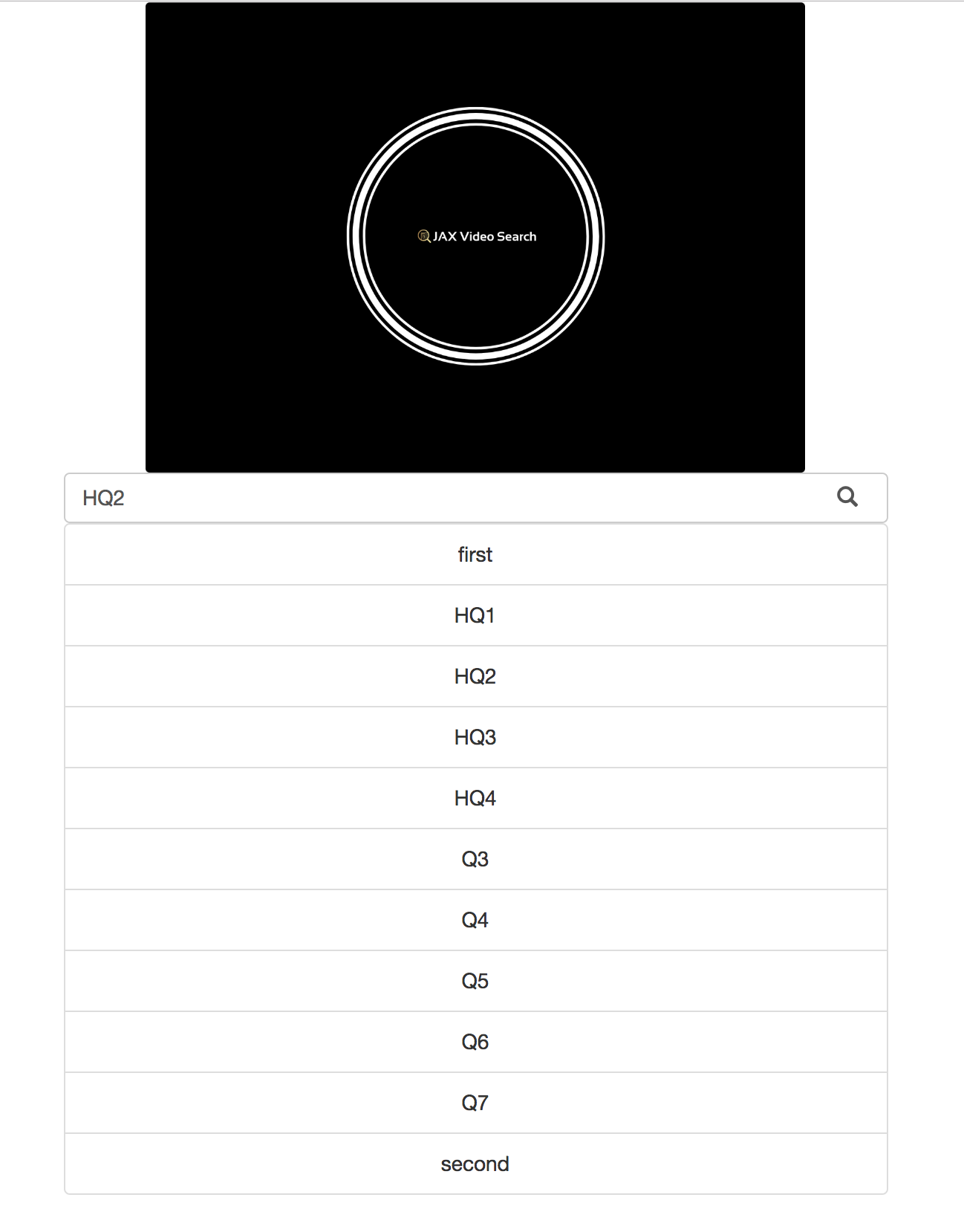
Screenshots of our project
Start_page with candidates:
Results page:
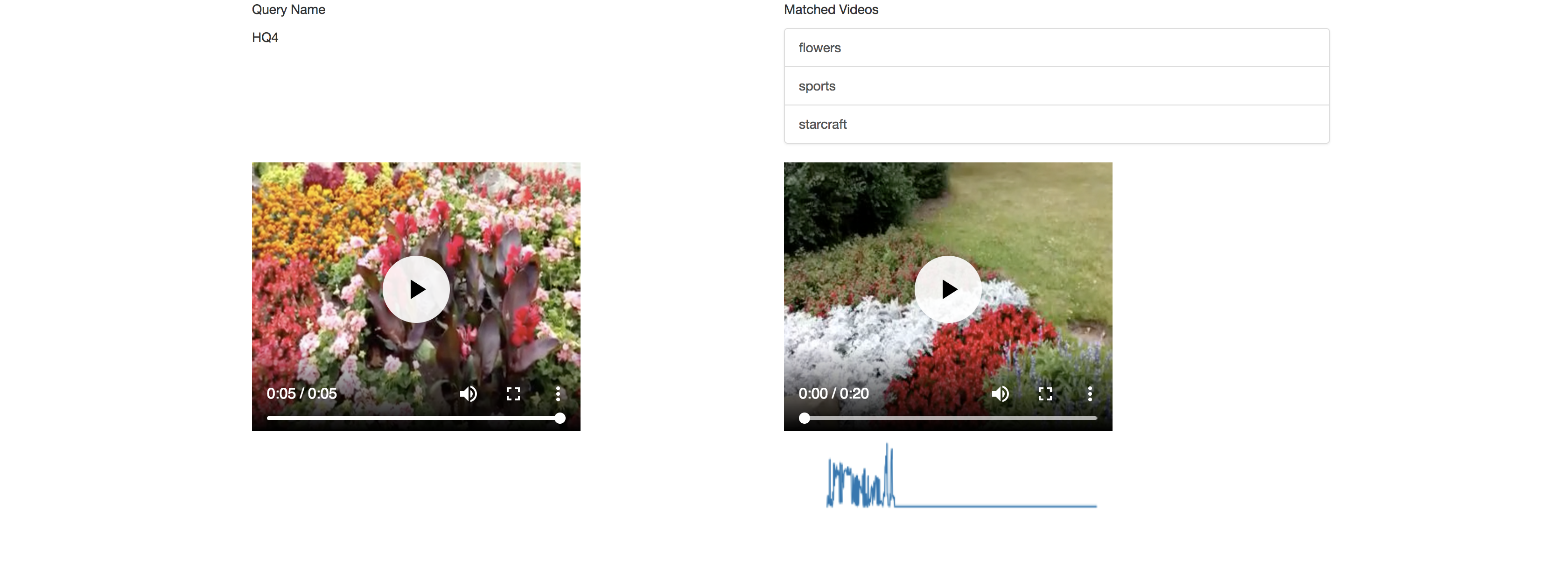
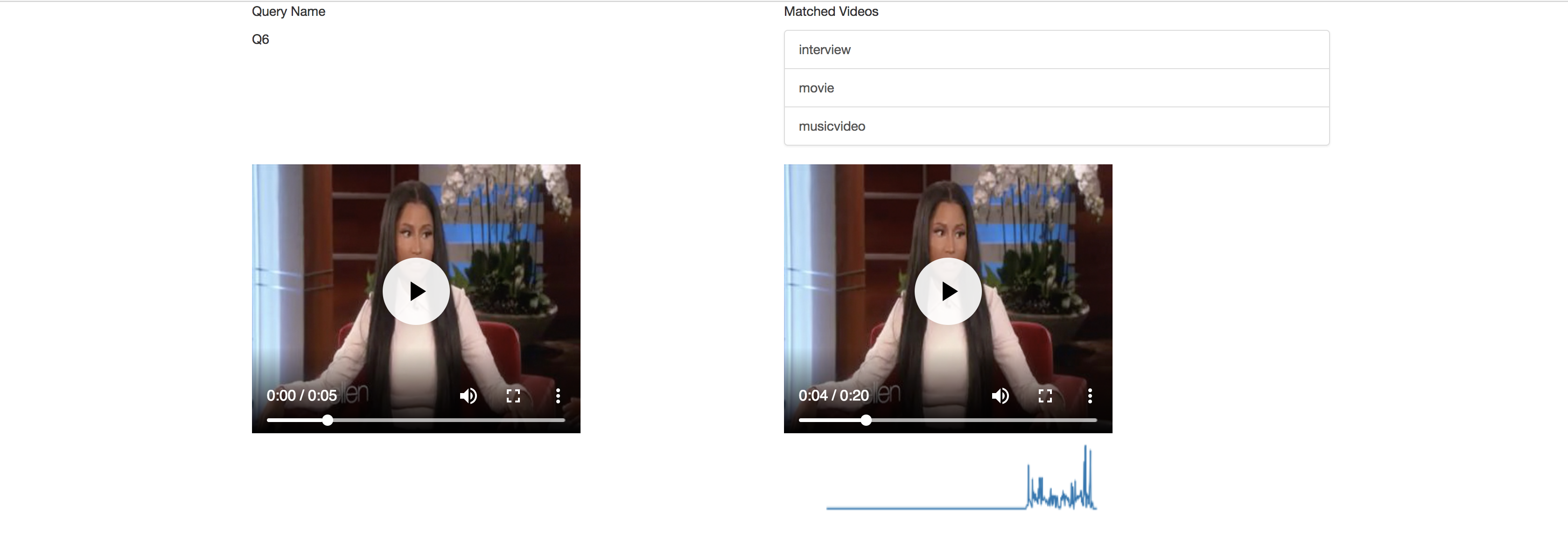
Improvement
Now our video search engine works, however, it doesn’t work very efficiently. For each query, it needs almost one minite to return the result, which is too long for a single query.
There are several possible methods that could improve it.
- Cache: we could store the previous query and its results. Also we could store some middle results, like the FFT results of audio data.
- Built-in library: use more build-in function, which has great possible to beat our own function.
- KD-Tree: use KD-Tree to accelerate the color query processing.
- More advanced algorithm: TBD, on the way to find more efficient and more accurate methods.
Conclusion
It’s a great trial for our group.
For project, it tries the different aspect of search engine, by using video clip directly.
However, it’s not only for the project itself, but also for the co-operation. We share ideas and are responsible for different parts of the whole task. We learn from each other and communicate better and better.
Thanks for my teammates, and the teacher and TA.