Probabilistic 3D Model Reconstruction
Team: Equilibrium
Members:
- Xingwen Zhang, xingwenz@usc.edu
- Qian Wang, wang215@usc.edu
Motivation
3D reconstruction with a 2D image is an important CV problem for robotics applications, such as manipulation, grasping and SLAM. However, robotics application has some specific necessity different from other computer vision tasks. The robot needs accurate 3D information for interacting, while there’re uncertain parts caused by occlusion or noise, the robot needs a probabilistic distribution of 3D structure, rather than one estimated result which may contain mistakes. We suggest a new method which can get high accuracy model in rich-information regions but the probabilistic model in occluded regions.
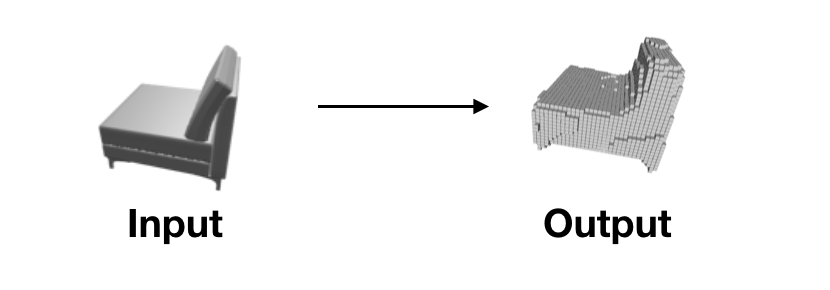
Reconstructing 3D model from a 2D image is an interesting topic. The reason why it’spossible is that we have prior knowledge of objects, so inferring missed informationfrom a 2D image is possible. However, the inference is not always accurate, since every specific object is somehow different from each other. Although we can get enough information of foresight surface for reconstruction, there’s always occluded surface we cannot accurately estimate. We need to represent those part with a probabilistic model for robot decision to avoid mistakes, but recent work can only get deterministic models, in which we cannot distinguish rich information regions (e.g.foresight surface) with low information regions (e.g. back-sight surface).
Approach
The overall approach is as follows:
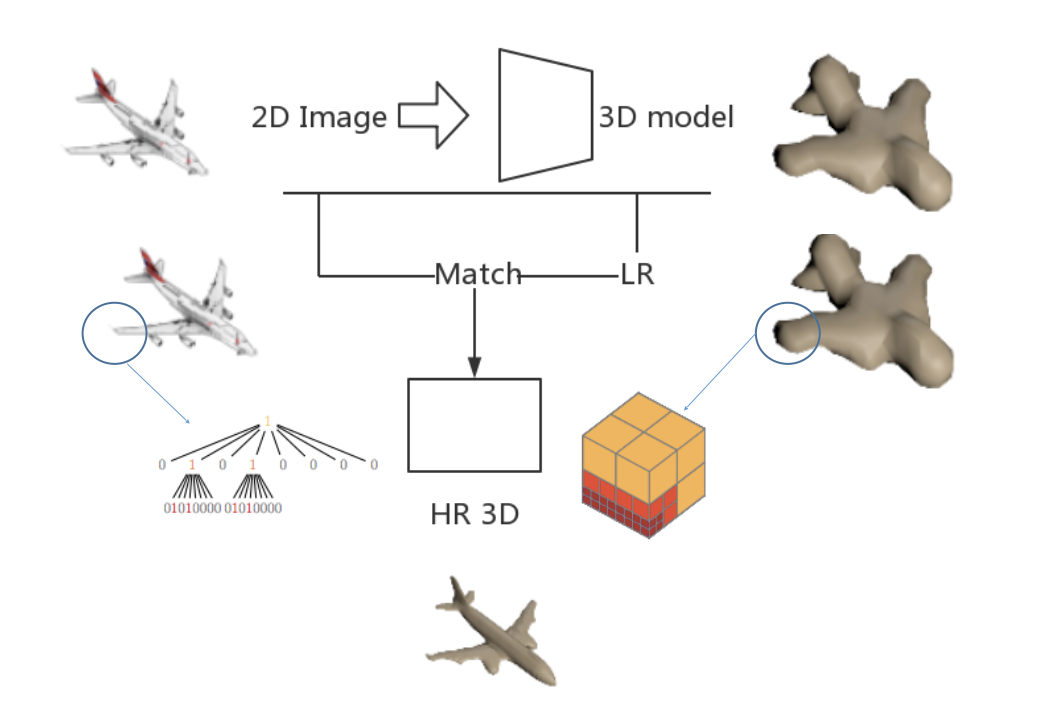
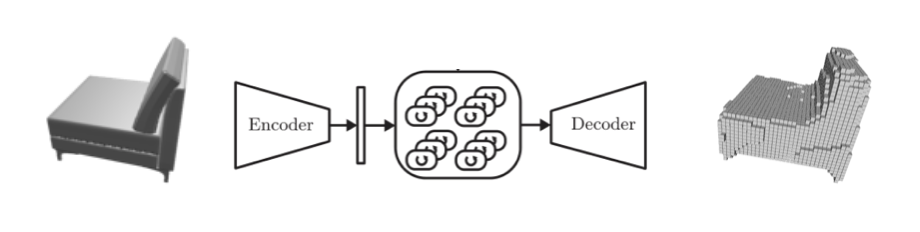
For initial 2D to 3D reconstruction method, we chose a LSTM basedmethod names 3D-R2N2. We use this method for two reasons:
- Recurrent network means we can generatemultiple different reconstruction results given different input information, which can help us to get result with different resolution to generate pyramid.
- This structure can use different gate to receive image from different view point, that means perhaps we can combine this network with our refining network which is used to improve resolution.
For visible surface detection, we simply use standard method(Visible Surface Detection) and label visible voxels. All those voxels are matched with relevant regions in raw 2d image.
Results
What has been done previously
There already several methods about the 3D reconstruction with single image or multiple image, one of the latest work is called Hierarchical surface Prediction for 3D object reconstruction, it divides the voxel types into three parts, empty, occupied and partial occupied, which is different from the other that divide voxel into two types, empty and occupied. This method could improve the accuracy of reconstructed 3D model.
At the same time, the basic method we use in this project is called 3d-r2n2, it is a unified multiple views and single view 3D reconstruction model. It could get pretty impressed results especially in multiple views.
The new part in our project
In our project, we step into the refinement of the reconstructed model. The aim of our project is to the refine the visible part of the reconstructed model, which could be useful in the future application like the robotic arm caption.
The first step for our project is to achieve the baseline method to reconstruct the 3D model. and then label visible parts of the model corresponding to input image, then we refine the visible part of the 3D model.
We use part of ShapeNet data as input of the model and reconstruct its 3D model, then take use of visible surface detection methods to show the visible part of the model and color it green.
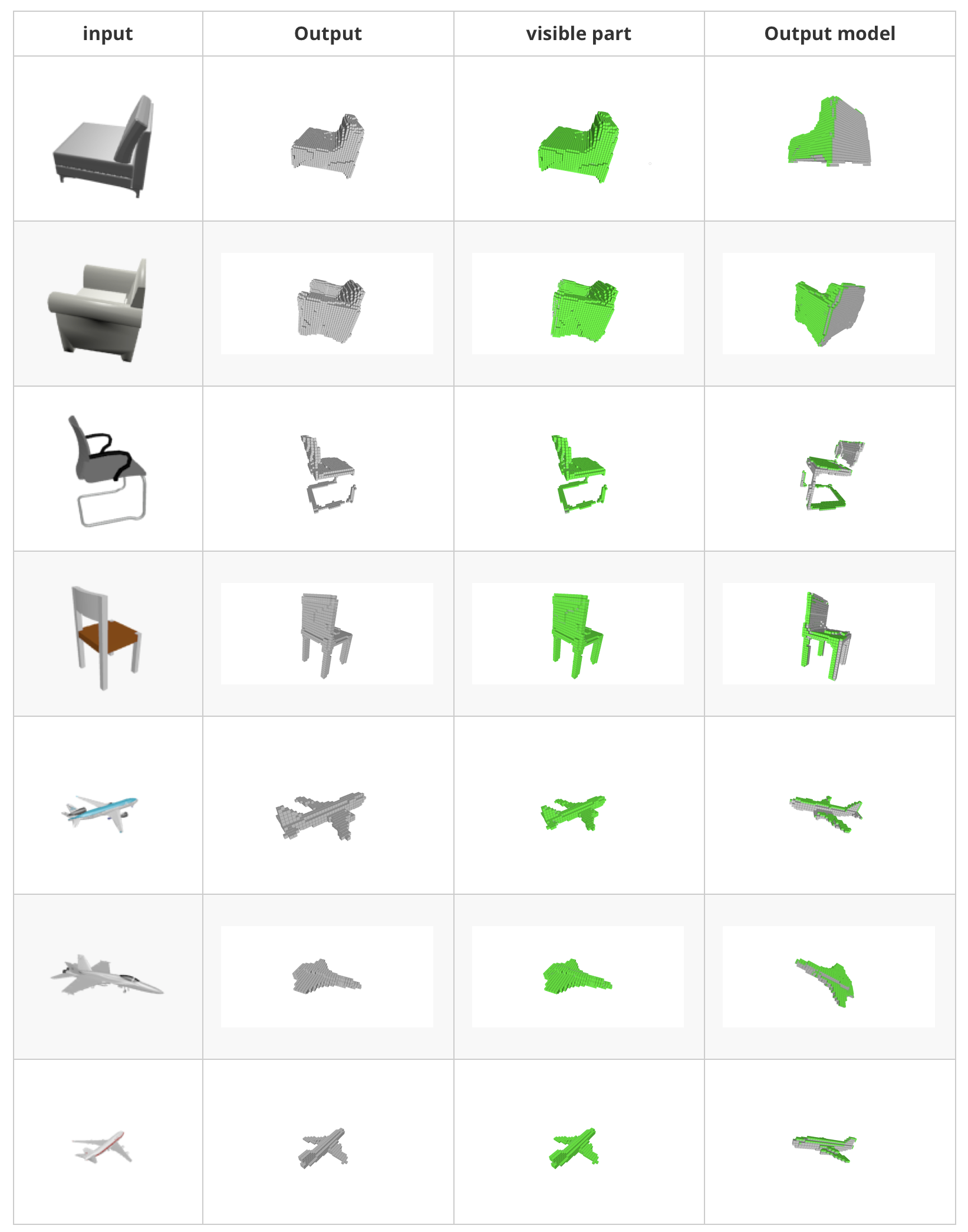
Refine the model
Given a roughly reconstructed 3D model, we now consider how to refine its visible surface. Using rendering technology in computer graphics, it is easy to find corresponding region in raw image for every voxel in 3D model.
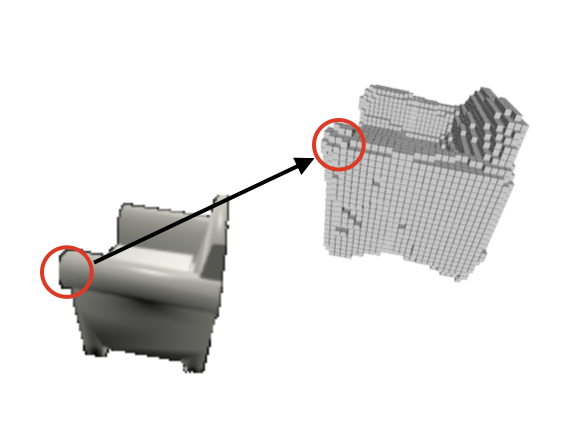
Given this region, what can we do with it? A natural idea is directly training a refining network with local raw image input and refined model output. The hypothesis behind this method is that given rough surface and raw image, it is possible to get (implicit/hidden) light and texture information by comparing them,
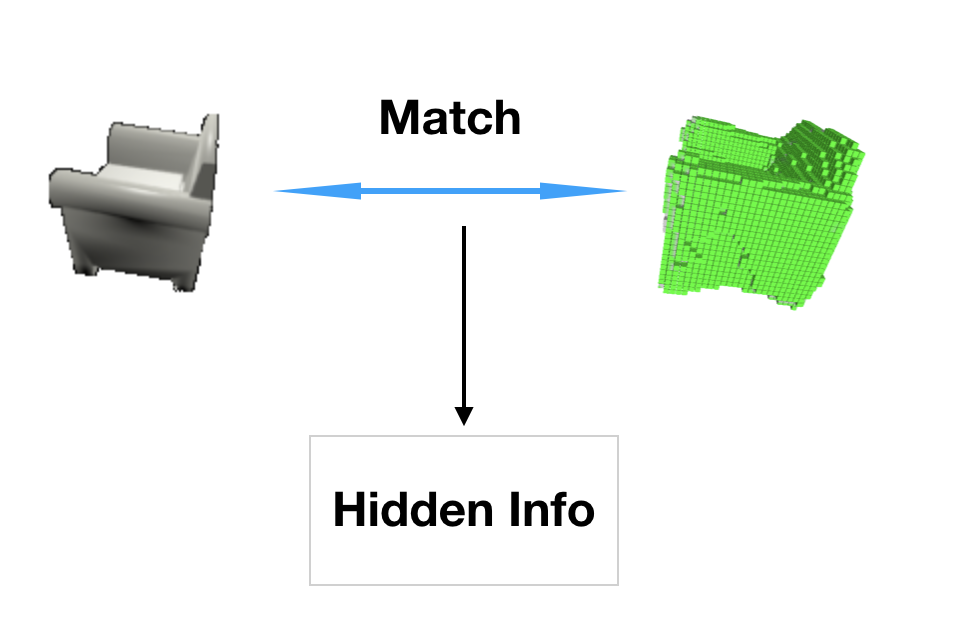
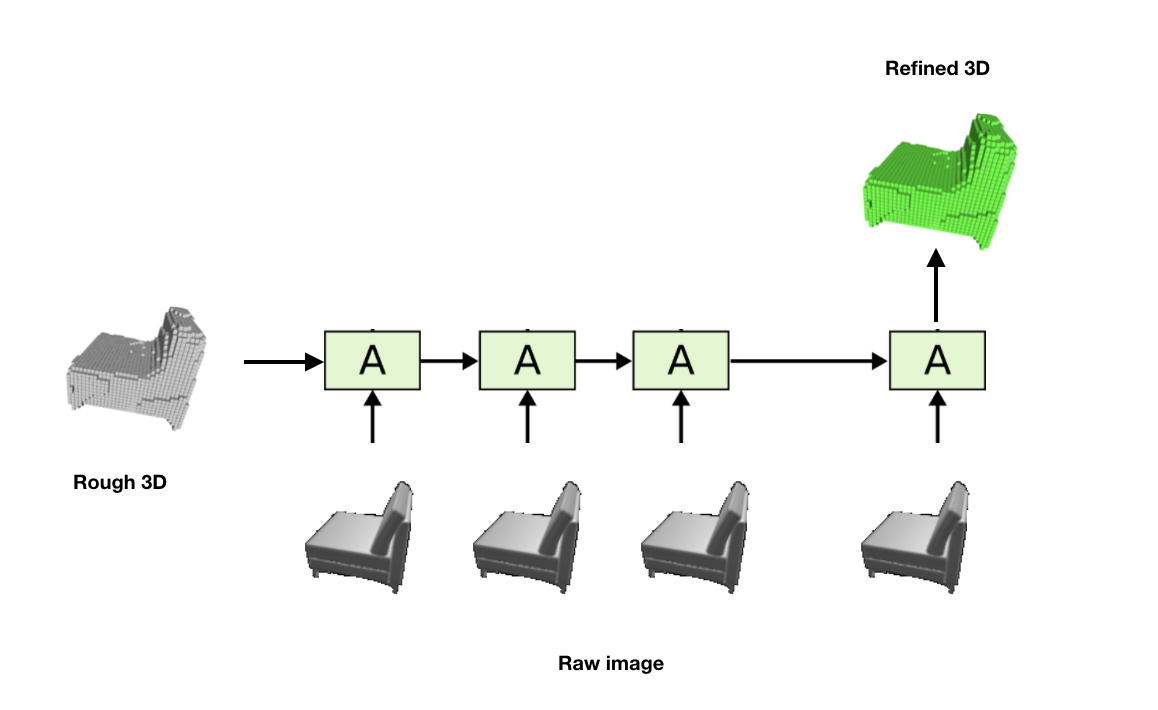
Then we can use this information and raw image to generate a refined 3D model. We designed a recurrent network model for that based on this hypothesis. But this approach is unstable because the hypothesis is not always correct.
Another idea is introducing stereo. Stereo method applies key points detection and match them between two images to generate 3D reconstruction,

But the reconstruction is sparse caused by the sparsity of invariant key points. However, our roughly reconstructed 3D model can work here, since the 3D reconstruction of 2 images is unique and matching a same voxel to different image can constrain matching regions.
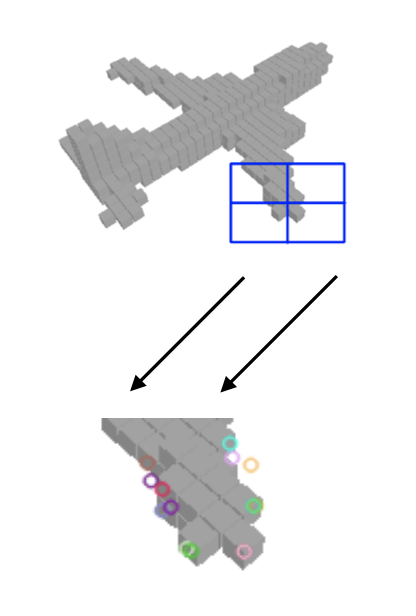
That makes it is possible to use variant features as key points, which is impossible in global image because of too many reduplicate candidates.
Conclusion
Although there are still a lot of work need to do, we think this could be a valueble way to improve the method about the 3D reconstruction within robotics field. The method presents a possible direction to refine the reconstructed model and improve the partial accuracy of the 3D model.
Reference
Choy, Christopher B., et al. “3d-r2n2: A unified approach for single and multi-view 3d object reconstruction.” European Conference on Computer Vision. Springer International Publishing, 2016.
Häne, Christian, Shubham Tulsiani, and Jitendra Malik. “Hierarchical Surface Prediction for 3D Object Reconstruction.” arXiv preprint arXiv:1704.00710 (2017).
Rezende, Danilo Jimenez, et al. “Unsupervised learning of 3d structure from images.” Advances in Neural Information Processing Systems. 2016.
Tatarchenko, Maxim, Alexey Dosovitskiy, and Thomas Brox. “Multi-view 3d models from single images with a convolutional network.” European Conference on Computer Vision. Springer International Publishing, 2016.
Riegler, Gernot, Ali Osman Ulusoys, and Andreas Geiger. “Octnet: Learning deep 3d representations at high resolutions.” arXiv preprint arXiv:1611.05009 (2016).
Girdhar, Rohit, et al. “Learning a predictable and generative vector representation for objects.” European Conference on Computer Vision. Springer International Publishing, 2016.